In the first stage of the coding, a three level spatio-temporal wavelet transform is applied to the motion sequences. Following [8], on the 3D subband structure, a spatio-temporal orientation tree naturally defines the spatio-temporal relationship on the 3D pyramid that results from the wavelet transformation. Reference [8] gives the only one reasonable parent-offspring linkage.
Once a three level spatio-temporal wavelet transform is applied to the sequences of images, although most of the energy is concentrated in the temporal low frequency, spatial residual redundancy in the high temporal frequency band does exist due to the motion. That is, there exists not only spatial similarity inside each frame across scales, but also temporal similarity between two frames. However, quantizer formation allows the exploitation of self-similarity across an spatio-temporal orientation tree using zerotree coding. The grouping and segregation of wavelet coefficients to form quantizers is achieved now by attention-based quantizer formation. In this formation process, wavelet coefficients of a 3D wavelet transform are partitioned into different quantizers by attention thresholding. It compacts points of maximum attention to a small number of high-attention quantizers.
Points ![]() of maximum attention can be calculated by searching for peaks in a local attention function. Local attention functions should be defined depending on the particular application of interest. We are here interested primarily in the transmission of sequences of moving targets (Section V). Since reference [9] demonstrates that velocity only accounted for forty-eight percent variation in the probability of target detection,
the local attention function is here computed to measure the velocity at any given point.
of maximum attention can be calculated by searching for peaks in a local attention function. Local attention functions should be defined depending on the particular application of interest. We are here interested primarily in the transmission of sequences of moving targets (Section V). Since reference [9] demonstrates that velocity only accounted for forty-eight percent variation in the probability of target detection,
the local attention function is here computed to measure the velocity at any given point.
Points ![]() of maximum attention are then signaled by peaks in the attention function
of maximum attention are then signaled by peaks in the attention function ![]() and thus, to detect points of maximum attention, the values
and thus, to detect points of maximum attention, the values ![]() can be thresholded using a global threshold:
can be thresholded using a global threshold:
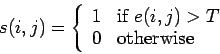 |
(5) |
The grouping and segregation of wavelet coefficients into a small number of quantizers
![]() , is achieved through quantizer formation using detected points of maximum attention as follows:
, is achieved through quantizer formation using detected points of maximum attention as follows:
Quantizer Formation Algorithm: