
|
|
|
Como ya hemos mencionado, el Lenguaje C++ está basado en la Programación Orientada a Objetos. Ésta se basa en el concepto de Abstracción, entendiéndose éste por “la capacidad de encapsular y aislar la información de diseño y ejecución”.
Vamos a ver los conceptos más
relevantes que nos ayuden a comprender mejor este paradigma.
| OBJETOS Y CLASES |
El concepto básico de la Programación Orientada a Objetos es el de Objeto, son las entidades básicas de ejecución.
Se podría definir un objeto como “un conjunto de operaciones que comparten un estado interno”. Las operaciones que es capaz de realizar un objeto determinan su interfaz y comportamiento. Se puede entender como una entidad de programa que contiene datos y todos aquellos procedimientos que pueden manipular esos datos.
Todos los objetos en un sistema orientado a objetos pertenecen a alguna Clase. La clase sirve como plantilla para la creación de objetos, que se conocen como instancias de la clase. La clase especifica el comportamiento común a todas sus instancias y la estructura de datos que soportará el estado de los objetos.
Antes de crear un objeto hay que definir su estructura y su funcionalidad, esto es, la clase del objeto. Por lo tanto, se puede definir una clase como una colección de objetos que poseen unas características y operaciones comunes. Las clases constituyen la base de la PDO, ya que constituyen las plantillas con las que se construirán los objetos.
Los objetos de una clase (sus instancias) se crean en tiempo de ejecución mediante el envío de mensajes a la clase, que producirán la ejecución de un método de clase. Cuando se crea un objeto, dispondrá de la estructura de datos y las operaciones propias de la clase.
El estado interno del objeto se representa mediante variables, que a su vez son objetos y cuyos valores se hallan ocultos al exterior y sólo pueden ser conocidos a través de los métodos (se dice que están encapsulados).
Hay dos tipos de variables:
![]() Variables
de instancia: son propias de cada objeto. Su declaración es igual a la
de cualquier variable en ‘C’.
Variables
de instancia: son propias de cada objeto. Su declaración es igual a la
de cualquier variable en ‘C’.
![]() Variables
de clase: comunes a todos los objetos de la misma clase. Hay un única
copia de cada variable y es accesible desde cualquier objeto de esa clase.
Variables
de clase: comunes a todos los objetos de la misma clase. Hay un única
copia de cada variable y es accesible desde cualquier objeto de esa clase.
Para declararlas hay que usar static.
La inicialización se hace aparte.
|
tipo_variable nombre_clase::nombre_variable=valor |
Por ejemplo,
|
class Producto { char* nombre; int precio_base; static int IVA; // … }; |
La relación entre clase y objeto es equivalente, por ejemplo, a la relación entre el concepto de persona y una persona en concreto. El concepto de persona engloba un conjunto de propiedades comunes a todos los seres humanos (seres vivos, mamíferos, inteligentes, altura, peso, nombre...) y una serie de funciones que los caracterizan (nacer, morir, comer, respirar, pensar...). A partir de esta clase persona se pueden obtener individuos concretos (personas), conocidos como objetos o instancias de la clase persona. Cada objeto tendrá unos valores concretos para las propiedades anteriores (Nombre: Alvaro Altura: 1,70 m Peso: 76 Kg).
De la misma forma que para utilizar un TDA es necesario disponer de la especificación del mismo, para poder utilizar una clase, o para incorporar una nueva subclase a la misma, se necesita disponer de la especificación de dicha clase.
Aunque podríamos establecer un método general de especificación de una clase, el cual tendría un aspecto muy similar a la de un TDA, pero incorporando el mecanismo de herencia (para indicar la jerarquía de clases), los lenguajes de programación orientados a objetos (LPOOs) necesitan especificar en su propia sintaxis las clases predefinidas y las definidas por el usuario, especificación que, además, está influenciada por el mecanismo de herencia implementado en el propio lenguaje.
Una clase Posee tres partes:
1. Private: Los miembros de este grupo sólo son accesibles desde dentro de la propia clase, o desde las clases declaradas como amigas.
2. Protected: El comportamiento de estos miembros es muy parecido al de los privados, con la salvedad de que también pueden acceder a ellos las clases derivadas (heredadas) de la clase que los contiene. Son los miembros protegidos.
3. Public: Los miembros públicos son aquellos a los que se puede acceder desde cualquier lugar de la aplicación. Constituyen la interfaz de la clase.
|
class nombre_clase { private: // datos y funciones privadas protected: // miembros protegidos public: // elementos públicos }
lista_de_nombre_de_objetos; |
Existen distintos tipos de clases:
1. Clase Base: Es una clase independiente, con características propias y no deriva de ninguna otra. Puede utilizarse de dos formas:
o Superclase
o Clase Abstracta
2. Clase Derivada: Es aquella que se obtiene a partir de la clase base, de tal forma que parte de las operaciones y elementos presentes en ésta se pueden conservar, redefinir, eliminar o añadir nuevos elementos.
|
class nombre_clase::public clase_de_la_que_deriva { // Elementos de la clase }; |
3. Clase Amiga: Una clase se considera “amiga” de otra cuando puede acceder a todos los elementos de la clase de que es amiga.
|
friend class nombre_clase_amiga; |
| FUNCIONES MIEMBRO |
La programación orientada a objetos consiste en definir clases y, por lo tanto, declarar objetos de ese tipo de clases. Para esto es para lo que sirven las funciones miembro, para definir el comportamiento de los objetos de una clase.
Su sintaxis es similar a la de las funciones, pero tiene una serie de peculiaridades:
- Si se definen fuera de la definición de la clase, hay que indicar el nombre de la clase a la que pertenecen.
- Al definirlas, se utiliza el operador de resolución de ámbito (:).
- Tienen acceso al objeto que ejecuta el método sin especificarlo como parámetro (mediante this).
- Los métodos nos permiten acceder a las componentes privadas de la clase.
Al igual que las variables, pueden ser funciones miembro de clase o instancia. En los métodos de clase se utiliza la palabra reservada static y no podrán ser virtuales.
Antes de utilizar una clase, todos sus miembros han de estar definidos.
Tenemos las siguientes funciones miembro:
1. Funciones miembro simples.
2. Funciones miembro amigas.
3. Funciones miembro en línea (inline).
4. Funciones miembro virtuales.
5. Funciones miembro constructoras:
o Constructores por defecto.
o Constructores sobrecargados.
o Constructores de copias.
6. Funciones miembro destructoras.
Declaración:
|
tipo_devuelto nombre (parámetros); |
Definición:
|
tipo_devuelto nombre_clase::nombre_función (parámetros) { //
Cuerpo de la función }; |
Son funciones que pueden acceder a los datos privados de una clase sin ser miembros de ésta. Ésto permite que varias clases distintas compartan algunas funciones.
Se definen en el cuerpo del programa sin que le preceda el nombre de la clase.
Para declararlas:
|
class nombre_clase { // … friend tipo_devuelto nombre_funcion (parámetros) // … }; |
Son funciones que se expanden en el lugar en que se referencian en vez de ser llamadas.
|
tipo_devuelto nombre_funcion (parámetros) { //
Cuerpo de la función }; |
El especificador que se utiliza cuando se definen fuera de la clase es inline. La sintaxis en este caso es la siguiente:
|
inline tipo_devuelto nombre_clase::nombre_función
(parámetros) { //
Cuerpo de la función }; |
Este tipo de funciones son las que permiten el polimorfismo. Son el soporte de las clases abstractas. Se declaran en la superclase y luego se redefinen en las clases derivadas.
El especificador con el que se definen es virtual.
Toda clase ha de tener, al menos, un método, llamado constructor. Es el método que se utiliza cuando se crea un objeto (se llama automáticamente).
Su tarea principal suele ser la de inicializar variables. Sus características son:
- Tienen el mismo nombre que la clase a la que pertenecen.
- Pueden tener (o no) parámetros.
- No devuelven ningún valor.
- No pueden ser virtuales ni de clase.
- Son public.
- Pueden definirse inline o fuera de la declaración de clase.
- Puede existir más de un constructor o, incluso, no haber ninguno.
Declaración:
|
nombre_clase (parámetros)
; |
Se definen exactamente igual que el resto de las funciones miembro.
Dentro de los constructores hay que destacar:
1. Constructores por defecto.
2. Constructores sobrecargados.
Por ejemplo,
|
class Factorial { int i; long
int l; public: // Dos constructores
int factorial (int i); long int factorial (long
int l); }; |
Definiciones:
|
int Factorial::factorial (int i) { i
= 1; }; long int
Factorial::factorial (long int l) { l = 1; }; |
3. Constructores de copias.
Declaración:
|
nombre_clase
(nombre_clase &) ; |
Por ejemplo,
|
class complejo { // … complejo (const complejo & original); // … }; |
Se suelen utilizar para deshacer alguna de las operaciones hechas por el constructor.
Sus características son:
- Tienen el mismo nombre que la clase pero van precedidos del símbolo “~”.
- No pueden tener argumentos.
- Tampoco pueden devolver nada.
- Pueden ser virtuales pero no static.
- Una clase no puede tener más de un destructor.
- El compilador llama automáticamente a un destructor del objeto cuando el objeto sale de su ámbito.
- Si no se declara, el compilador crea un destructor por defecto.
|
~nombre_clase (parámetros) ; |
Los métodos, a su vez, también pueden ser definidos como públicos o privados; éstos últimos sólo pueden ser utilizados por la propia clase. Cualquier otro código que no es miembro de la clase no puede acceder a un método o variable privado, lo que asegura que no se van a producir accesos no permitidos.
Al conjunto de los métodos públicos de la clase se le llama interfaz y permite la comunicación entre objetos. Existen ciertos lenguajes que no son tan estrictos respecto a este tema, puesto que dejan definir variables tanto privadas como públicas, es decir, accesibles directamente por los demás objetos. No obstante, esta práctica no es recomendable.
Para terminar, señalar el hecho de que todas las entidades son objetos, por tanto todas las clases del sistema deben ser objetos con propiedades comunes. Este conjunto puede ser definido por una "nueva clase" que describa propiedades comunes a todas ellas. Este concepto se denomina Metaclase y tiene por instancias las otras clases del sistema. Así, se permite ver las clases como objetos.
| ENCAPSULAMIENTO DE DATOS |
El encapsulamiento es el mecanismo que permite mantener los datos y los métodos que manejan esos datos alejados de posibles usos indebidos.
Se trata de agrupar, de alguna forma, datos + capacidad de procesamiento. Asociado a esta agrupación hay una interfaz que nos da acceso a esos datos y a esa capacidad de procesamiento. Desde el exterior, los usuarios sólo pueden ver el comportamiento de los objetos, desde el interior, los métodos proporcionan el comportamiento apropiado por medio de las modificaciones del estado.
La única forma de acceder a los objetos es a través de mensajes: nada saben otros objetos de sus variables de instancia (su representación) y del código de los métodos. Es decir, se puede modificar la implementación de dichos métodos (por ejemplo, para hacerlo más eficiente) sin variar su interfaz.
| TIPOS DE DATOS |
En
un lenguaje de programación el concepto de tipo es de gran importancia. Cada
variable, constante o expresión del mismo tiene un único tipo asociado con
ella. En C++ la asociación de un tipo con una variable se realiza en su
declaración, mientas en otros lenguajes es posible prescindir de la
declaración. En la implementación del lenguaje, la información referente al
tipo, determina la forma en que las operaciones aritméticas tienen que
interpretarse y capacita al compilador a detectar errores en aquellos programas
que no las utilizan de forma apropiada.
Las características del concepto
de tipo pueden resumirse en los siguientes puntos:
1.
Un tipo determina la clase de
valores que pueden tomar las variables y expresiones.
2.
Todo valor pertenece a uno y
solo un tipo. Esta correspondencia única permite manejar el valor sin
ambigüedad dado que siempre existe un único tipo y por tanto una única
interpretación de las conversiones de
tipo que facilite el lenguaje.
3.
El tipo de un valor denotado por
una constante, variable o expresión puede deducirse de su forma o contexto, sin
ningún conocimiento de su valor calculado en el momento de ejecución.
4.
Cada operador está definido para
operandos de varios tipos, y calcula el resultado obteniendo un tipo que esta
determinado por el de éstos (usualmente el mismo si son iguales).
5.
Cuando el mismo símbolo se
aplica a diferentes tipos (la suma, +, para los enteros y los reales), este
símbolo puede considerarse como ambiguo, denotando diferentes operadores según
el tipo de operandos a que se aplique. La resolución de la ambigüedad puede
realizarse siempre en el momento de compilación.
6.
Las propiedades de los valores
de un tipo y de operaciones primitivas se especifican formalmente.
7.
La información del tipo en un
lenguaje de programación se usa, por una
parte para prevenir errores, y por otra, para determinar el método de
representar y manipular los datos en un ordenador.
8.
Los tipos más importantes son
precisamente los más importantes dentro de las matemáticas: Producto
Cartesiano, Unión Discriminante, Conjuntos, Funciones, Sucesiones, Estructuras
Recursivas, etc.
| HERENCIA Y COMPOSICIÓN |
Nosotros
buscamos definir tipos de datos
abstractos (TADs). Un inconveniente de los TADs es que definen una caja negra, una vez definidos no
interactúan con los programas que los utilizan. Así, no es posible adaptarlos a
nuevas aplicaciones sin modificar su definición, resultando poco flexibles en
este sentido. Considérese, por ejemplo, la definición de un tipo Figura en un
sistema gráfico que maneja círculos, cuadrados y triángulos, y supóngase que se
dispone de los TADs Punto y Color. Se podría definir el tipo Figura de la forma
siguiente:
Especificación
parcial
|
Tipo Figura Declaración de tipos Punto, Color, Especie, Entero, Figura Características Un objeto de este tipo
es una figura geométrica de centro y color conocido. Operaciones función Crear_Figura
(e:Especie; c:Color; p:Punto; ...) retorna
Figura { Necesita: un indicativo e de la especie de figura, un
color c, un punto p y ...
(para la representación). Produce: una figura de la
especie e, con color c y centro en p. } función Centro (f:Figura) retorna
Punto { Necesita: una figura. Produce: el punto central de
la misma. } acción Mover (f:Figura; p:Punto) { Necesita: una figura f y un punto p. Modifica: la figura f con
nuevo centro en p. Efecto: imprime en la
salida estándar la figura. } acción Girar (f:Figura; n:Entero) { Necesita: una figura f y un entero n. Modifica: la figura f
girándola n grados alrededor de
su centro. Efecto: imprime en la
salida estándar la figura. } acción Dibujar (f:Figura) { Necesita: una figura. Efecto: imprime en la
salida estándar la figura. } ..................... fin Figura |
Implementación parcial
|
Type Especie = (circulo,
cuadrado, triangulo); Figura = ^datos; datos = record col:Color; c:Punto; case e:Especie of circulo: {
representación para un círculo} cuadrado: {
representación para un cuadrado } triangulo: {
representación para un triángulo } end; procedure Dibujar (f:Figura) begin case f^.e of circulo: {
dibujar círculo } cuadrado: {
dibujar cuardrado } triángulo: {
dibujar triángulo } end end; |
El tipo Figura tiene un claro inconveniente:
es necesario un campo que determine la especie de la figura (círculo, cuadrado
o triángulo). Esto es así por dos razones:
1. Los campos necesarios para
representar cada figura pueden ser distintos.
2. Hay operaciones, como por
ejemplo Dibujar, que deben distinguir entre los distintos tipos de figura para
que se realicen correctamente.
y, por tanto, si se quieren
incorporar nuevas figuras es necesario modificar la implementación del tipo. Es
decir, no se pueden incorporar más figuras a menos que se tenga acceso a la
implementación de éste, lo que va en contra del objetivo que se perseguía con la
utilización de los TADs.
El problema que se
ha planteado con el tipo Figura se debe a que no hay distinción entre las
propiedades generales de cualquier figura (una figura tiene un color, puede ser
dibujada, etc.) y las propiedades de una figura específica (un círculo es una
figura que tiene un radio, se dibuja mediante una función de trazado de
círculos, etc.). Expresar esta distinción y aprovecharla es lo que define a la
programación orientada a objetos (POOs en adelante). Para ello en este estilo de programación se incorpora lo
que se conoce como mecanismo de herencia.
En POOs a un tipo
de dato se le denomina clase, a una
variable o instancia de la clase objeto
y a las operaciones del tipo de dato métodos.
La herencia permite organizar jerárquicamente las clases que se necesiten para
resolver un determinado problema, de modo que si una clase precede a otra en la
jerarquía se dice que ésta es una clase
derivada o subclase de la
primera, y recíprocamente, la primera es la clase base o superclase
de la segunda. Aunque el mecanismo de herencia no es tan trivial, sobre todo si
una clase puede tener varias superclases (herencia múltiple), la idea es que
una subclase hereda los campos y métodos definidos en sus superclases.
Algunas de las
ventajas de la herencia son:
![]() Reutilización
del software: cuando el comportamiento se hereda de otra clase, no
necesitamos rescribir el código responsable de ese comportamiento. Además,
aporta mayor confiabilidad: cuanto más utilicemos ese código, mayores serán las
posibilidades de encontrar errores.
Reutilización
del software: cuando el comportamiento se hereda de otra clase, no
necesitamos rescribir el código responsable de ese comportamiento. Además,
aporta mayor confiabilidad: cuanto más utilicemos ese código, mayores serán las
posibilidades de encontrar errores.
![]() Compartición
de código: muchos usuarios o proyectos independientes pueden hacer uso
de las mismas clases. Podemos referirnos genéricamente a estas clases como
componentes software. Otra forma de compartición de código ocurre cuando un
programador construye dos o más clases diferentes que heredan de una clase
paterna única.
Compartición
de código: muchos usuarios o proyectos independientes pueden hacer uso
de las mismas clases. Podemos referirnos genéricamente a estas clases como
componentes software. Otra forma de compartición de código ocurre cuando un
programador construye dos o más clases diferentes que heredan de una clase
paterna única.
![]() Consistencia
de la interfaz: si tenemos un conjunto de clases que heredan de la
misma superclase, se asegura que el comportamiento que heredan será similar en
todos los casos. Así, es más fácil garantizar que las interfaces de objetos
similares tengan comportamientos similares, y al programador se le hace más
fácil recordar la manera en que éstos objetos se utilizan.
Consistencia
de la interfaz: si tenemos un conjunto de clases que heredan de la
misma superclase, se asegura que el comportamiento que heredan será similar en
todos los casos. Así, es más fácil garantizar que las interfaces de objetos
similares tengan comportamientos similares, y al programador se le hace más
fácil recordar la manera en que éstos objetos se utilizan.
![]() Ocultación
de información: cuando se desarrolla un componente software sólo se
necesita entender la naturaleza del componente y su interfaz. Es decir, no
importa comprender cómo se ha implementado dicho componente.
Ocultación
de información: cuando se desarrolla un componente software sólo se
necesita entender la naturaleza del componente y su interfaz. Es decir, no
importa comprender cómo se ha implementado dicho componente.
Los criterios para
establecer una jerarquía de clases son varios pero normalmente nosotros nos
basaremos en alguno de los dos siguientes:
1. Obtención de subclases por
especificación.
2. Obtención de subclases por
especialización.
Así para el
ejemplo sobre figuras visto anteriormente podría establecerse la siguiente
jerarquía de clases:
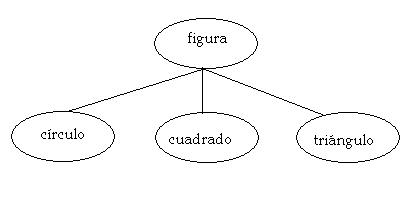
Jerarquía de clases
No debe
confundirse la herencia con la composición, ambos son mecanismos de
reutilización de software que están disponibles en los lenguajes de
programación orientados a objetos, pero mientras la herencia es un mecanismo
propio del estilo de este de programación orientado a objetos, el mecanismo de
composición era ya ampliamente utilizado en los lenguajes de programación
imperativos (como, por ejemplo, C o Pascal).
El mecanismo de
composición permite definir un nuevo tipos de dato (o clase) utilizando en su
representación uno o varios tipos de datos (o clases) ya conocidos y establece
una relación del tipo tiene un entre las instancias del nuevo
tipo de dato y los tipos de datos que lo componen. Por el contrario, el
mecanismo de herencia establece una relación del tipo es un entre
las instancias de una subclase y la clase (o clases) base.
Las heurísticas
para crear subclases son diversas (algunos autores citan hasta ocho) sin
embargo nosotros nos limitaremos a las más habituales: la clasificación por
especificación y la clasificación por especialización.
En la clasificación por especificación la
clase base proporciona una especificación, pero no la implementación. El
propósito de la clase base es definir qué debe hacerse, pero no cómo debe
acometerse la tarea, es la subclase la que por redefinición de los métodos de
la clase base proporciona la implementación. Esto ocurre, por ejemplo, con el
método Dibujar de la clase Figura, ya que esta clase debe indicar que todas las
figuras se pueden dibujar (debe implementarse un método para ello) pero la
implementación del método debe desarrollarse en cada una de las subclases ya
que depende de la figura específica a dibujar.
En la clasificación por especialización las
instancias de las subclases tienen alguna característica o propiedad adicional
que no tienen las instancias de la clase base. Esto hace que sea necesario bien
redefinir algún método de la clase base para adaptarlo a las nuevas
características, bien que las subclases incorporen algún campo nuevo para
almacenar el valor de éstas, o bien ambas cosas. Esto ocurre, por ejemplo, con
cada una de las subclases de la clase figura que, al menos, deben incorporar
los campos necesarios para representar cada una de las figuras específicas
(círculo, cuadrado, triángulo).
Con este estilo de
programación el problema que se planteaba con el TAD Figura (era necesario
acceder a la implementación del tipo para incorporar nuevas figuras)
desaparece. En este caso para añadir una figura específica únicamente se
necesita crear una nueva subclase de la clase Figura e incorporar los métodos y
campos específicos de la misma.
La herencia es una característica que cuenta con la propiedad transitiva. Por ejemplo, la clase Figura, tiene unas características, si después se crea una clase que hereda de ésta llamada Círculo, con sus características propias, heredará los miembros de la clase Figura. Si ahora se crea una nueva clase que heredara de Círculo, por ejemplo la clase Elipse, ésta heredaría los componentes de la clase Círculo y por transitividad los de la clase Figura. Esta propiedad es muy importante por que es la que permitirá realizar jerarquías de clases de gran complejidad partiendo de elementos más o menos simples que se van heredando de una clase a otra.
No obstante existe la posibilidad de eliminar o modificar características heredadas en las subclases mediante anulación y redefinición respectivamente.

Objetos de la clase Figura
Finalmente, se conoce como herencia múltiple a la posibilidad de que una clase herede de varios padres. Esta propiedad nos va a permitir modelizar los objetos del mundo real cuando se tienen varias visiones de los mismos. Por ejemplo, se puede tener una clase Cafetería, otra clase Sala de ordenadores, y por último, una clase que se llame Cibercafé que herede de las dos a la vez.
La herencia múltiple presenta un grave problema, que se presenta si varias clases padres tienen miembros con un mismo nombre. Como no todos los lenguajes de programación tienen un método para implementar la herencia múltiple existen varias maneras de evitarla reestructurando la jerarquía de clases.
| LIGADURA DINÁMICA Y POLIMORFISMO |
El polimorfismo es una característica que
permite definir abstracciones que pueden ser utilizadas por objetos de
diferentes tipos. Podríamos, por tanto, tener una colección que contuviera una
mezcla de objetos de modo que después podríamos recorrer la colección y enviar
a cada objeto de ésta el mismo mensaje.
Así, por ejemplo,
en el caso de las figuras podríamos definir una abstracción correspondiente a
un conjunto de figuras y un método, DibujaTodo, que permita dibujar cada una de
las figuras que contiene (círculos, cuadrados y triángulos). Ahora bien, para
ello es necesario que en la invocación al método Dibuja la ligadura con la
instancia a la que se aplica se realice en tiempo de ejecución (no es posible
en tiempo de compilación), ya que ésta puede ser un círculo, o un cuadrado, o
un triángulo, o bien una instancia de cualquier nueva subclase de la clase
figura.
La ligadura se refiere a la resolución de
las referencias existentes en un texto de programa. En los lenguajes de programación la ligadura (binding) entre los
parámetros actuales de la invocación a una función y los correspondientes
parámetros formales de la declaración de la misma, puede ser de dos tipos: estática (realizada en tiempo de
compilación) y dinámica (realizada
en tiempo de ejecución).
En los lenguajes
tradicionales como, por ejemplo, el Pascal la ligadura es estática, mientras
que en los LPOOs la ligadura es dinámica. De esta forma el sistema determina de
forma automática la función adecuada dependiendo del tipo objeto encontrado y
el programador no necesita realizar test basados en el tipo del mismo.
Una
variable también puede cambiar su tipo en tiempo de ejecución, en este caso se
dice que es polimórfica, pude tomar varias formas o ser de diferentes tipos
durante toda su vida. Si son los objetos los que cambian en tiempo de
ejecución, igualmente se les llama polimórficos.
Para que se pueda dar polimorfismo, las variables y objetos deben almacenarse en la parte de la memoria que se corresponde con el heap y no en el stack. El heap permite que el espacio de memoria reservado para las variables pueda cambiar en tiempo de compilación y ejecución, que es lo que ocurre cuando su tipo o clase cambia, mientras que el stack no lo permite.
Un ejemplo para aclarar el polimorfismo puede ser el siguiente:
1) Clase Persona. Tiene un método "canta" cuya especificación es entonar una canción y cuya implementación incluye la canción 'La la la la...'. Si se crea un objeto Alvaro de la clase Persona y se le envía el mensaje canta, responderá: 'La la la la...'.
2) Clase Ladrón. Hereda de la clase Persona (los ladrones son personas). Tiene un método canta cuya especificación es entonar una canción y cuya implementación incluye la canción: 'Yo no he sido'. Si se crea un objeto "Luis" de la clase Ladrón y se le envía el mensaje canta, responderá: 'Yo no he sido'
Objeto Luis de la clase Ladrón, se le envia a Luis el mensaje canta y éste responde: 'Yo no he sido'.
En tiempo de ejecución Alvaro puede especializarse y cambiar de clase, convirtiéndose en un objeto de la clase Ladrón. Al enviar el mensaje canta a Alvaro, es otro método el que se ejecuta, el de la clase Ladrón, y no el que se ejecutó cuando era solamente una persona.
El polimorfismo de método ha evitado tener que cambiar el mensaje que se envía a Alvaro, y ha permitido que, dependiendo de la clase a la que pertenezca el objeto en cada momento, el método que se invoque sea diferente. Es muy útil cuando en tiempo de ejecución no se si Alvaro es una Persona o un Ladrón pero se que el programa funcionará y que cantará de una u otra manera.
Un ejemplo de sobrecarga sin polimorfismo es el que viene dado por el mensaje +. Hay lenguajes donde + se utiliza para sumar números y para concatenar cadenas de caracteres. La especificación es diferente, luego tenemos sobrecarga.
| ABSTRACCIÓN DE ITERADORES |
Como sabemos el
mecanismo de herencia puede utilizarse para varios propósitos, entre otros: la
definición de subclases por especificación. Como se recordará, en este caso la
clase base define qué debe hacerse pero no cómo debe hacerse, lo que será
establecido por las subclases.
Una de las aplicaciones
más importantes de la clasificación por especificación es la definición de
abstracciones iterativas. Un iterador facilita el acceso a los elementos de
colecciones (estructuras de datos con varios elementos) ignorando los detalles
de implementación de las mismas y de las operaciones propias de la colección.
En los lenguajes
de POOs es habitual que exista una clase iteradora abstracta que especifica las
operaciones necesarias para obtener los elementos de una colección, en caso
contrario, siempre podría definirse.
Para poner de
manifiesto la ventaja de utilizar iteradores en el acceso a colecciones (el
acceso es independiente de como se represente la colección y de las operaciones
definidas para ésta) veremos un ejemplo sencillo: la suma de una colección de
enteros. Supongamos que la colección se representa mediante dos estructuras: un
vector v[1..n] ] con (n³0) y
una lista l. Entonces, los algoritmos
que permiten, en cada caso, obtener la suma de todos los enteros podrían ser
los siguientes:
|
función suma (v:Vector) retorna
Entero; var s,i:Entero; inicio s:=0;
i:=0; mientras i¹n hacer i:=i+1; s:=s+v[i]; fmientras; retorna
s ffunción |
función suma (l:Lista) retorna
Entero; var n:Entero; inicio
si lista_vacía(l) retorna 0 sino n:=primer_elemento(l); retorna n+suma(resto_elementos(l) fsi ffunción |
Es de destacar que
la finalidad de ambos algoritmos es la misma y, sin embargo, cada uno de ellos
depende de las operaciones definidas para la colección. En el caso de que la
operación este representada mediante un vector se utiliza la operación [], y en el caso de que este
representado mediante listas se utilizan las operaciones: lista_vacía, primer_elemento
y resto_elementos.
En definitiva, se
puede decir que si el acceso a colecciones de elementos depende de la
representación de la colección o de las operaciones de las mismas, entonces, si
se elige una nueva representación para la colección es necesario modificar los
programas que las utilizan.
La abstracción por
especificación permite evitar este problema, ya que entonces la iteración se
realizaría sobre la base de las operaciones abstractas y cada colección tendría
asociado su propio iterador que no sería más que la implementación de dichas
operaciones. Obviamente, éstas si dependerían de la representación concreta de
cada una de las colecciones.
Podemos
plantearnos qué operaciones debería tener todo iterador, operaciones que
estarían especificadas en la clase abstracta. Ya que el orden en que se
obtienen los elementos de la colección es indiferente (exceptuando, quizá, si
las colecciones son ordenadas), para tratar los elementos de la colección
podemos considerar que ésta es una secuencia con un primer elemento arbitrario.
De esta forma para tratar los elementos de la colección, sólo tenemos que
aplicar el esquema habitual de recorrido en el que todos los elementos de la
secuencia tienen el mismo tratamiento:
|
obtener_primer_elemento; mientras hay_elemento? hacer tratar(elemento_actual); obtener_elemento_siguiente fmientras |
Precisamente, las
operaciones que se han reseñado en cursiva son las que, al menos, debería
incluir un iterador; es decir:
·
una operación para inicializar el iterador y, si la colección no está
vacía, obtener el primer elemento de la misma (obtener_primer_elemento).
·
una operación que indique si hay elementos en la colección sobre la
que se itera (hay_elemento?)
·
una operación para obtener el elemento actual (elemento_actual)
·
una operación para pasar al siguiente elemento de la colección (obtener_elemento_siguiente)
Ahora podríamos reescribir el algoritmo para
sumar los enteros de una colección en la forma:
|
suma:=0 obtener_primer_elemento mientras hay_elemento? hacer suma:=suma+elemento_actual; obtener_elemento_siguiente fmientras |
el cual es independiente de la
representación de la colección. Ya sólo tendríamos que implementar un iterador
para la misma: un iterador para vectores, un iterador para listas, etc.

Iteradores
| TIPOS DE DATOS ABSTRACTOS |
A la hora de especificar la solución a un problema es muy importante hacerlo de forma adecuada, siguiendo un determinado orden.
Un tipo de dato abstracto (TDA) es un conjunto de objetos, junto con una familia de operaciones definidas sobre dicho conjunto. Hay que tener en cuenta dos puntos sobre este nuevo concepto:
![]() Es un tipo de dato. El hecho de construir
un nuevo tipo de dato abstracto nos va a ofrecer una nueva clase de objetos que
en términos de programación se traducirá en uno o varios nuevos tipos definidos
por el usuario.
Es un tipo de dato. El hecho de construir
un nuevo tipo de dato abstracto nos va a ofrecer una nueva clase de objetos que
en términos de programación se traducirá en uno o varios nuevos tipos definidos
por el usuario.
![]() Es una abstracción. Es decir, trabajamos
a nivel de información superior, obviando los detalles que no son relevantes
cuando se usa el nuevo tipo.
Es una abstracción. Es decir, trabajamos
a nivel de información superior, obviando los detalles que no son relevantes
cuando se usa el nuevo tipo.
Para definir un TDA de manera
que se pueda usar necesitamos realizar una especificación
del TDA y para ello hay que tener en
cuenta:
![]() Los objetos que usamos. Esto conlleva la necesidad de definir el dominio en donde tomará
valores una entidad que pertenezca a la nueva clase de objetos.
Los objetos que usamos. Esto conlleva la necesidad de definir el dominio en donde tomará
valores una entidad que pertenezca a la nueva clase de objetos.
![]() Cómo usar los objetos. Para poder saber la forma en que podemos usar los objetos tendremos
que resolver dos puntos:
Cómo usar los objetos. Para poder saber la forma en que podemos usar los objetos tendremos
que resolver dos puntos:
* Cómo hacer referencias a una
operación. Por lo tanto debemos solucionar un problema de sintaxis: realizar
una especificación sintáctica, es decir, las reglas que hay que seguir para
hacer referencia a una operación.
* Qué significado o consecuencia tiene cada
operación. Debemos solucionar un problema de semántica: realizar una especificación semántica.
Identificar y describir el
dominio de un TDA es generalmente sencillo. Hay distintas formas de hacerlo:
![]() Si el dominio es finito y
pequeño, éste puede ser enumerado. Así como el dominio del tipo booleano, es
decir, true y false.
Si el dominio es finito y
pequeño, éste puede ser enumerado. Así como el dominio del tipo booleano, es
decir, true y false.
![]() En otro caso se puede hacer
referencia a otro dominio conocido de objetos matemáticos. Por ejemplo,
En otro caso se puede hacer
referencia a otro dominio conocido de objetos matemáticos. Por ejemplo,
·
El conjunto de los enteros positivos.
·
El conjunto de los números complejos con módulo menor o igual que 1.
![]() Otras veces un dominio se puede
definir constructivamente, es decir,
enumerando unos cuántos miembros básicos del dominio y proporcionando
reglas para generar o construir los miembros restantes a partir de los
enumerados. Por ejemplo en domino de las cadenas de caracteres puede definirse
como sigue:
Otras veces un dominio se puede
definir constructivamente, es decir,
enumerando unos cuántos miembros básicos del dominio y proporcionando
reglas para generar o construir los miembros restantes a partir de los
enumerados. Por ejemplo en domino de las cadenas de caracteres puede definirse
como sigue:
·
Cualquier letra es una cadena.
·
Cualquier cadena seguida de una letra es una cadena.
Este tipo de definiciones se llaman también definiciones recursivas, ya que hacen referencia a los elementos del dominio definido para crear nuevos elementos.
La especificación sintáctica de
un tipo es bastante sencilla. Consiste en determinar cómo hay que escribir
dichas operaciones, dando el tipo de operandos y el resultado. Por ejemplo, el
tipo entero se puede especificar sintácticamente, enumerando las siguientes
operaciones:
|
+ : integer x integeràinteger
- : integer x integeràinteger
== : integer x integeràboolean
abs : integeràinteger |
Otra forma más relacionada con la forma de escribirlo en un lenguaje de programación es:
|
Int ’+’ (int a,b)
Int ’-‘ (int a,b)
Unsigned char ‘==’ ( int a,b) Int abs ( int a) |
Este tipo de especificaciones
tiene la siguiente interpretación: + es una función que se aplica sobre dos
enteros y te devuelve un entero. Cuando se escriben entre comillas, como en el
caso de +, significa que al aplicarla a dos valores enteros hay que expresarlo
en su forma infijo: operando1 operador operando2. La función abs que no está
entre comillas se expresa en la forma usual de la función, abs (a).
Una vez conocida la sintaxis de
las operaciones de un TDA hay que especificar su significado. Éste se puede dar
de distintas formas. La primera es mediante el uso de lenguaje natural. El
problema asociado al uso del lenguaje natural es que éste puede dar lugar a
ambigüedades. Por ejemplo, si decimos que ‘div’ divide un entero entre otro,
esto puede dejar lugar a dudas sobre cómo funciona realmente este operador. Una
buena especificación debe identificar todas las posibles opciones que puedan
ocurrir. Serían más adecuados por tanto decir: “el valor de ‘x div y’ es la
división entera de x entre y despreciando el resto. El valor no está definido
cuando y es igual a 0”. Se puede
pensar que cuando se requiera más precisión se debe utilizar una notación más
matemática. Otro tipo de especificación es especificación algebraica. Consiste
en dar un conjunto de axiomas que son verificados por las operaciones asociadas
a los objetos en cuestión son más útiles para los tipos simples o primitivos.