Next: First-Best Test Data Classification Up: Regularized Logistic Regression Previous: MAP Estimates with Laplace
Stochastic gradient descent (SGD) is a general method for optimizing parameters given the partial derivatives of the error function relative to the parameters [Bottou 1998].
![\begin{displaymath}
\nabla_{c,i} \ \textrm{Err}_R(D,\beta,\sigma^2)
=
\frac{\par...
...d \beta) - \log p(\beta \mid \sigma^2)\right)\nonumber\\ [6pt]
\end{displaymath}](img32.png) |
For logistic regression, the error function is a sum of contributions of the individual training cases and parameters, with the derivatives distributing through to individual cases.
The derivatives distribute through the cases for the data log likelihood:
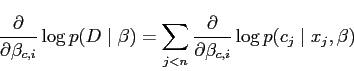 |
(7) |
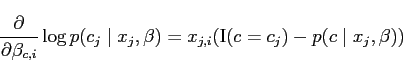 |
(8) |
The derivatives also distribute through the parameters for the
Laplace prior:
![\begin{displaymath}
\frac{\partial}
{\partial \beta_{c,i}} \log p(\beta_{c,i} \...
..._i} & \textrm{if } \beta_{c,i} < 0 \\ [6pt]
\end{array}\right.
\end{displaymath}](img38.png) |
(9) |
Although stochastic gradient is very fast at finding rough solutions, it required tens of thousands of iterations over all of the data to converge within several decimal places.
Training for the large feature systems required on the order of 20 machine hours on a single-threaded single-process estimator. Training of the reduced feature set experiment was quite fast.